
The Research Excellence Framework (REF) is the UK’s system for assessing the quality of research in UK higher education institutions (HEIs). Institutions are invited to make submissions in 34 subject-based units of assessment (UoAs). For each submission, three distinct elements are assessed by an expert panel: the quality of outputs (e.g., publications, performances, and exhibitions), their impact beyond academia, and the environment that supports research. The most recent REF was held in 2021, and the results, including detailed analysis and the full dataset of submitted outputs, are available on the REF website.
Inspired by Professor Simon Tanner’s research on the REF2014 data for the Academic Book of the Future project, Jisc wanted to drill down into the REF2021 data to provide a snapshot of books and chapters published in the REF reporting period by UK-based authors. To do this, we cleaned the underlying data and used it to create an enhanced dataset; we then performed detailed analysis with a focus on the research output types comprising of books or parts of books: authored books, edited books, scholarly editions, and book chapters.
This blog post explains the methodology for cleaning and enhancing the REF2021 dataset, outlines what we have achieved from the exercise, and next steps.
What did we do?
The REF2021 dataset comprised of over 185,000 submissions from 157 UK HEIs. Cleaning measures were applied to the entire dataset, including all output types such as journal articles, to produce an enhanced version of the dataset that could be used by different audiences where applicable.
Initial cleaning steps included cleaning and cross checking Persistent Unique Identifiers (PIDs) such as DOIs, ISSNs and ISBNs, and adding further bibliographic data using the Crossref open API.
Extensive work was undertaken to clean the Publisher value, for those outputs listing a traditional publisher, to more accurately determine the hierarchy of publishers in terms of number of publications. The number of unique publishers was reduced from 5,624 to 4,436 using both automated and manual processes. Further standardisation could be achieved for publisher names by creating a new column to identify where the identified publisher was an imprint of a larger parent company.
Focusing on the four output types that we defined above as Books, or parts of books, 23,740 outputs were imported into Microsoft Power BI to create visualisations that summarise and explore trends surrounding the landscape of UK long-form publishing from 2014 onwards. We will share these visualisations and accompanying analysis in greater detail in a forthcoming publication.
Analysis of the data
Analysis of the enhanced dataset can be performed in order to gain insight into publishing trends affecting UK-based authors over the course of the seven-year REF2021 reporting period. Users of the data can benefit from a higher level of standardisation than in the raw data (especially for the Publisher and Parent company fields) to gain a more accurate picture of the UK publications landscape. Although we acknowledge that the REF2021 data is in itself a subset of the total academic book output for UK HEI.
Jisc’s own analysis has focused on long-form publications, for example in Figure 1, shows the number of submissions for the four output types by year.
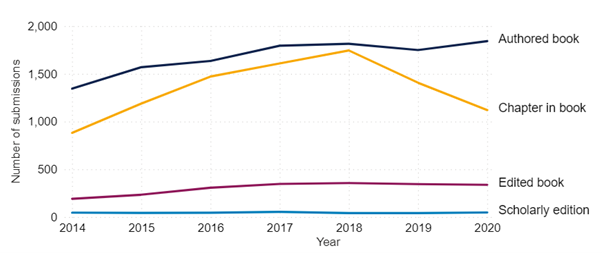
Figure 1. Submission of books and book chapters to REF 2021. Datasource: REF 2021 submissions dataset
Next steps
This data cleaning and subsequent analysis has informed our work supporting the implementation of the UKRI Open Access (OA) policy for longform publications (monographs, book chapters and edited collections become in-scope of the policy from 1st January 2024), as well as informing discussions surrounding the next REF exercise in 2028.
The enhanced dataset is available to download from Zenodo with a CC0 license. Interested parties are encouraged to download the data for their own analytical purposes and share their own analysis.
Find out how Jisc is supporting the research community to implement the UK Research and Innovation (UKRI) open access policy.
