Second SDP 3C Shared Task – Evaluating Automated Methods for Citation Classification

The need for administering automated methods for evaluating research is gaining more attention lately. The primary motivation for this is to replace the regular, more exhausting exercises like peer-reviewing and the not so sophisticated, less accepted ways of ranking research works like Impact Factors, which solely depend on the citation-frequency. One such proposition is the utilisation of other citation aspects, such as function or importance, for redefining the current research evaluation decision frameworks. The recently concluded 3C citation context classification shared task – organised by the researchers at Knowledge Media Institute (KMi), The Open University, UK and the Oak Ridge National Laboratory (ORNL), US – is one such effort aimed at providing a unifying platform for researchers in this domain, to push research further in this direction.
The second 3C shared task was organised as part of the 2nd Workshop on Scholarly Document Processing (SDP), a prominent event comprising key players in this domain, concurrently associated with the 2021 NAACL conference. As with the previous version, this year too, we chose Kaggle InClass competitions for hosting both Substask A (Purpose Classification) and Subtask B (Influence Classification), because of the platform’s simplicity in setting up the tasks. Both tasks used a portion of the ACT citation classification dataset. A major difference this year though was the release of full text dump of the citing papers in addition to the 8 fields in the ACT dataset, with an aim to investigate whether this could improve the performance of the systems submitted by the participants.
Both competitions were a huge success in terms of the active participation of more teams from across the globe. We received a total of 22 submissions for purpose classification and 19 for the influence task. The tables below show the private leaderboard for both Subtasks. The submissions by the team IREL, employing SciBERT for representing citation context, received the highest private score of 0.26973, finishing as winners for the purpose task. Meanwhile, for the influence task, we did not receive a paper or code submission from the team, which finished as first on the private leaderboard. Hence, based on the criteria for winning this shared task, the team IREL was declared as winners for this subtask too.
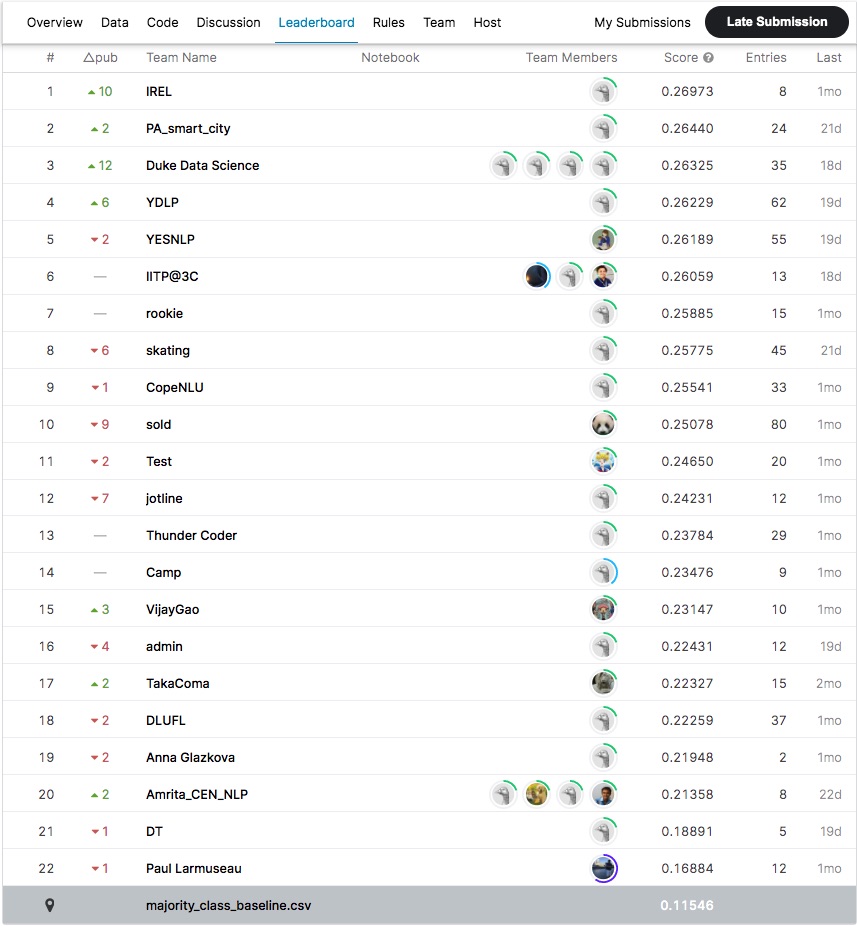
Fig 1 : Purpose classification – Private leaderboard
The submitted papers and the source code from the participating teams show the use of Deep Learning based methods for the purpose classification task, unlike the first shared task. One of the teams even extended the citation context in the dataset by using the previous and the next context, thus utilising the full-text data dump. This year also witnessed the usage of external datasets (ACL-ARC and SciCite) for improving the results. An overview of the SDP 3C shared task has been documented as a long paper. This paper along with all the shared task papers accepted to SDP will be published shortly in ACL Anthology (so stay tuned for that). In the meantime, all these papers are available for access from the shared drive. A comparison of results from both the subtasks with the existing state-of-the-art models indicates room for more research, especially with multi-disciplinary dataset.
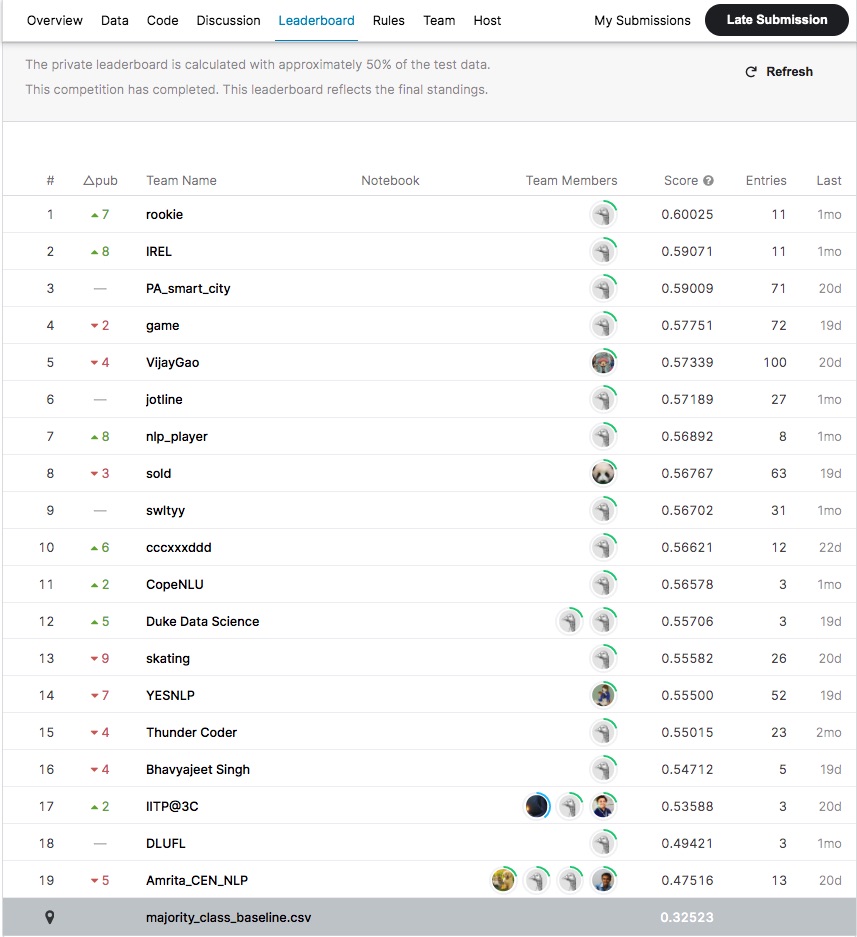 Fig 2: Influence Task – Private leaderboard
Fig 2: Influence Task – Private leaderboard
Acknowledgement
This shared task was organised by the researchers at KMi, The Open University, UK and Oak Ridge National Laboratory, US and funded by Jisc.